




Un proxy è un programma che si interpone tra un client ed un server inoltrando le richieste e le risposte dall’uno all’altro. Il funzionamento è semplice: il client che esegue una richiesta si collega al proxy invece che al server e gli invia delle richieste; il proxy si collega al server e inoltra le richieste del client, riceve le risposte e le inoltra al client. In ambito aziendale i proxy possono essere sfruttati in vari modi: possono filtrare i contenuti che transitano sulla rete dei dipendenti, possono bloccare determinate connessioni, possono analizzare le informazioni che provengono dalla rete per, ad esempio, mettere in pratica soluzioni di Data loss prevention (DLP). Ecco perché dedicheremo ai proxy due articoli in modo da introdurre il lettore ad alcune soluzioni open source più utilizzate.
Tipi di proxy
Possiamo inizialmente suddividere tali programmi in proxy di livello applicativo, che si occupano di inoltrare solamente i dati inerenti un particolare protocollo (HTTP, FTP, …) e proxy di tipo SOCKS, che inoltrano le connessioni TCP/UDP (le quali, ricordo, formano un “involucro” per i protocolli superiori) in toto, senza entrare nel merito appunto dei protocolli di livello più alto al loro interno trasportati. Questi ultimi tipi di proxy risultano applicabili quindi a più protocolli applicativi anziché esser costruiti specificatamente per uno solo tra essi, ma risultano poco malleabili e poco adattabili alle caratteristiche peculiari degli stessi. Per tali motivazioni vengono spesso “relegati”, certamente con ottimi risultati, alla protezione della privacy degli utenti. Nel presente articolo tratteremo i proxy di livello applicativo HTTP, cioè atti alla navigazione Web. In tale tipo di proxy, il client viene ad identificarsi con il browser ed il server con il web server. Tutti i browser della LAN dovranno essere configurati per uscire sull’Internet per mezzo del proxy – tramite impostazioni dello stesso browser, del sistema operativo, tramite topologie di rete ad hoc oppure anche tramite l’inusitato protocollo WPAD. Delle due tipologie possibili di proxy appplicativi HTTP ci occuperemo dei forward proxy, che, contrapponendosi ai reverse proxy, fungono da “gateway” per la navigazione Web. Un (forward) server proxy HTTP può essere impiegato principalmente per i seguenti scopi:
- cache: un caching proxy mantiene copia locale delle risorse Web precedentemente richieste da altri client, in modo da portare, se usato in una rete, ad effettivi risparmi di banda, servendo le risorse in memoria in luogo delle risorse remote per le successive richieste. Il protocollo HTTP prevede header appositi per la gestione ottimale della cache, tuttavia opportuni accorgimenti devono esser attuati affinché la copia locale non sia desincronizzata rispetto a quella remota (talvolta ciò crea problemi);
- filtraggio dei contenuti: un content filtering proxy viene spesso utilizzato in scuole ed organizzazioni al fine di impedire l’accesso a contenuti ritenuti non conformi alle politiche aziendali (contenuti per adulti, contenuti considerati non attinenti al lavoro svolto, file troppo grandi, file potenzialmente pericolosi e/o possibile veicolo di malware, e via discorrendo). Il filtraggio si attua generalmente tramite analisi dell’URL, del dominio, del formato di file delle risorse Web e del loro contenuto testuale; per quest’ultimo controllo viene solitamente usata la corrispondenza dello stesso a determinati pattern/stringhe. È possibile reperire sulla Rete ed utilizzare delle blacklist di URL, domini e pattern da filtrare;
- logging: è possibile che un proxy venga utilizzato come sistema di logging delle connessioni Web dei client dell’organizzazione. Al fine di controllo (leggi vigenti permettendo) o per semplice reportistica;
- privacy: un server proxy può esser utilizzato per mascherare la vera sorgente (indirizzo IP – con ovvietà se su rete diversa – e browser) del traffico Web. Dipendentemente dalla qualità dell’anonimato fornito, queste tipologie di proxy vengono suddivisi in anonimi ed altamente anonimi. I proxy altamente anonimi nascondono gli indirizzi IP, non aggiungono header HTTP che possano palesarne la presenza, nascondono le tracce del browser utilizzato e, molto importante, non devono mantenere informazioni di log sulle connessioni effettuate, cioè informazioni su quali client ad esso si connettono e quando.
Come già accennato, l’intento del presente articolo è quello di presentare alcuni tra i più utilizzati programmi di proxying HTTP, open source, con particolare occhio rivolto alla compatibilità per sistemi Unix-derivati, che fanno della stabilità, dell’alta configurabilità e del costo nullo le loro eccellenti – e vincenti – bandiere di guerra. Cominciamo con Apache.
Squid
Squid è il caching proxy HTTP per antonomasia; software open source, è compatibile con tutti i sistemi Unix-derivati, quali: Linux, BSD, Mac OS X, Solaris ed altri. HTTP non è l’unico protocollo di livello applicativo supportato da Squid, ma chiaramente il più utilizzato e quello che ha donato al programma la sua attuale fama. La sua stabilità, velocità, sicurezza e facile reperibilità di documentazione per il corretto utilizzo rendono Squid adatto tanto ad utilizzi per SOHO, small office/home office, quanto ad utilizzi professionali, che rimangono comunque il target implicito del software: un programma così complesso risulta di difficile comprensione e di ostica configurazione per alcuni; la lunghezza del suo solo file di configurazione è a prima vista disarmante. Il memory footprint del programma, al contrario di quello di Tinyproxy, è, inoltre, molto elevato, per scelta progettuale di massimizzazione delle performance – parte della cache viene tenuta in memoria. Da ciò deduciamo che questo proxy server risulta particolarmente disadatto a macchine vecchie e/o dispositivi ARM Linux-powered, sempre più di moda. Caratteristiche principali (in ordine sparso) sono, oltre a quanto già detto:
- il supporto ad SSL;
- la possibilità di esser utilizzato come anonymous proxy;
- la possibilità di esser utilizzato come reverse proxy;
- il filtraggio dei contenuti (anche mediante espressioni regolari sul testo delle pagine HTML);
- il vasto numero di moduli che ne vanno ad ampliare le funzionalità (es.: DansGuardian per un ottimale filtraggio dei contenuti);
- la possibilità di monitoring remoto via SNMP;
- le differenti metodologie di autenticazione delle connessioni in ingresso (ActiveDirectory authentication, LDAP authentication, altro; direttiva acl);
- le funzionalità che fanno seguito alla profilazione utenti sono molto duttili: è per esempio possibile abilitare la navigazione in distinti giorni ed orari per distinti utenti;
- il caching per le ricerche DNS;
- il caching gerarchico distribuito su più proxy Squid in rete (direttiva cache_peer);
- la restrizione dei download ed il controllo antivirus sulle risorse Web (con ClamAV);
- un sistema di logging certosino: vengono salvate le informazioni sull’accesso, sugli errori e sul consumo di risorse di memoria e filesystem.
Troviamo certamente anche qui la possibilità di far girare il proxy come utente non root (direttiva cache_effective_user) ed un’elevata configurabilità delle sue opzioni di cache. Squid è, in definitiva, il miglior caching proxy HTTP open source disponibile e si configura come la scelta ideale per l’uso professionale (incoraggiato anche dai numerosi servizi di supporto commerciale), rimanendo definitivamente escluso solamente ove vi siano necessità di “leggerezza” e/o assoluta facilità di utilizzo. Uno tra i nomi eccellenti di questo utilizzo professionale è senz’altro Wikipedia, che usa un insieme di proxy Squid al fine di minimizzare il carico dei sottostanti web server Apache e database, come visibile dalla figura riportata qui sotto.
Figura 1:
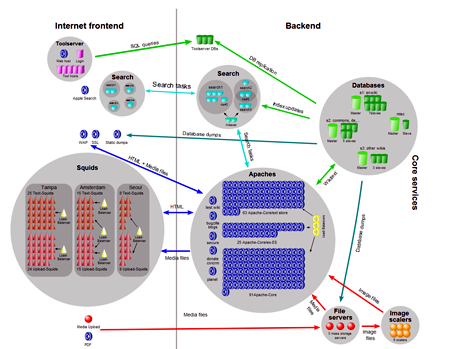
Su Wikipedia stesso si legge che il sistema di proxy Squid è in grado di quadruplicare la capacità di banda dei suoi server Web, data la natura fortemente “statica” dei suoi contenuti.
Privoxy
Privoxy è un filtering proxy HTTP particolarmente adatto alla protezione della privacy dell’utente mediante funzionalità di anonymous proxy: modifica gli header HTTP in transito e blocca gli ads (script pubblicitari) e gli elementi che potrebbero vanificare ogni altro sforzo di nascondimento delle tracce (Java, Flash). È infatti noto che applet Java ed oggetti Flash potrebbero iniziare una connessione HTTP svincolata da quella del browser stesso, e quindi in taluni casi senza passare per il proxy. Come ogni altro server proxy qui presentato, è utilizzabile sia su singolo host che in rete, locale LAN od Internet. Se non utilizzato assieme a Tor, come di solito è, le sue peculiarità di filtraggio degli ads (blocco script pubblicitari, banner, popup, eccetera) vengono rese piuttosto inutili dalle estensioni atte al medesimo scopo presenti su Firefox (quale Adblock Plus per esempio). Chiaramente, per contro, un amministratore di rete potrebbe volerlo implementare in luogo di Squid/DansGuardian quale filtering proxy su una rete non molto estesa. In questo senso, oltre a possedere, inevitabilmente, il controllo degli accessi di chi ad esso si connette (ACL), svolge le sue funzioni di filtro in base alle regole descritte in alcuni suoi file di configurazione, il più importante dei quale è default.action, che contiene una blacklist di URL e domini da filtrare, parzialmente compilata dagli autori del programma (per la sola funzione di ad blocker e similare) ed aggiornata periodicamente.
Apache
È possibile configurare il web server Apache affinché funzioni come un proxy HTTP (filtering, caching, balancer,…), compatibile, come noto, con tutti i più diffusi sistemi operativi, *nix, Windows e molti altri. La stabilità di Apache e la sua larga diffusione, nonché la completezza delle sue funzionalità in generale e di proxy nello specifico fanno però da contrappunto alla sua “pesantezza” in termini di memory footprint, cioè di risorse di memoria occupate: qualora la “leggerezza” del proxy divenisse requisito fondamentale (pensiamo ad esempio ad applicazioni per device mobili), Apache potrebbe non rivelarsi la scelta ideale. Chiaramente, in ogni altro caso, Apache svolge eccellentemente il suo dovere. Scendendo nel dettaglio, il modulo mod_proxy di Apache trasforma il noto web server in un forward (e, volendo, anche reverse) proxy HTTP/0.9, HTTP/1.0 e HTTP/1.1, con supporto SSL. Le funzionalità del proxy vengono attivate abilitando, secondo le esigenze, i moduli di interesse: mod_proxy_http, mod_proxy_ftp, mod_proxy_ajp, mod_proxy_balancer e mod_proxy_connect. In aggiunta, a complemento della tipologia di proxy desiderato (di nostro interesse è il proxy HTTP) abbiamo mod_cache, il quale trasforma il proxy HTTP in cache proxy HTTP e mod_ssl che permette al proxy stesso connessioni tramite tunnel sicuro SSL. Mod_cache a sua volta può utilizzare diversi storage al fine di salvare le risorse in cache: il modulo accessorio mod_disk_cache implementa un caching su disco, mentre mod_mem_cache su memoria RAM.
Caching
Apache può essere semplicemente utilizzato come una risorsa per conservare in cache le navigazioni. Una possibile configurazione di esempio del modulo di caching di Apache è la seguente (è stato attivato mod_disk_cache, quale metodologia di salvataggio):
CacheRoot “/tmp/proxyCache/”
CacheMinFileSize 64
CacheMaxFileSize 65535
CacheMaxExpire 86400
La precedente configurazione impone ad Apache di:
- utilizzare /tmp/proxyCache come cartella per lo storage dei dati di cache (esistono altre opzioni disponibili per il “tuning” di tale cartella);
- considerare una risorsa “cachabile” solo se di peso compreso tra 64 e 65535 byte;
- considerare come vecchie le copie dei file nella cache dopo al massimo 86400 secondi.
La direttiva CacheDisable non menzionata, permette di elencare URI per i quali non verrà abilitata la funzionalità di caching. Ci si riferisca alla documentazione ufficiale per uno sguardo a tutte le rimanenti direttive.
Filtraggio dei contenuti
Al fine di impedire l’accesso a contenuti ritenuti non conformi alle politiche aziendali (content filetring proxy), generalmente vengono utilizzati strumenti differenti, quali, ad esempio, Squid in unione con DansGuadian. Tuttavia, la direttiva ProxyBlock di mod_proxy attua una forma basilare di filtraggio: Apache può esser istruito per bloccare l’accesso alle risorse definite dalla lista di parole, URL o domini passati come parametro alla direttiva.
Tinyproxy
Tinyproxy è un filtering proxy HTTP molto leggero per sistemi *nix. I suo autore, oltre che sulla semplicità di utilizzo e sulla sicurezza, pone l’accento sulla leggerezza del footprint del programma, ciò che lo rende di fatto un candidato ideale per ogni tipo di device Linux-based, quale router, NAS, smartphone, eccetera, oppure anche per vecchi server o PC. Semplicità in un software di questo tipo significa possibile impiego anche in ambito domestico, qualora – e non è un utilizzo raro – un padre volesse dare una fruizione di Internet consona alla loro età ai suoi figli piccoli. Per ciò che concerne la sicurezza interna del programma, è presente anche qui la consueta possibilità di far girare il servizio come utente non root (dopo l’avvio ed il bind con le porte TCP). Ciò è importante perché, in caso di exploit, viene ridotto il rischio di compromissione dell’intero sistema (un programma “crackato” può eseguire codice all’interno del sistema solamente con i permessi dell’utente con cui in esso gira). Sempre a detta dell’autore e sempre riguardo la sua sicurezza, la progettazione del software è stata fatta con occhio di riguardo alla prevenzione dai buffer overflow. Probabile… però una veloce ricerca con Google non smentisce simili vulnerabilità passate. Dal punto di vista dell’utilizzatore, invece, tra le caratteristiche del proxy annoveriamo la possibilità di fungere da proxy anonimo, potendo anche manipolare la lista degli header HTTP visibili o no al server destinazione, ed il supporto all’SSL. Altra caratteristica interessante è la possibilità per il proxy di negare connessioni ad esso se viene superata una certa percentuale di carico della macchina su cui gira (cosa buona per macchine poco potenti). Infine, va segnalata la funzionalità di monitorare il proxy da remoto al fine di visualizzare i dettagli degli accessi ed altre statistiche. Riprendendo quanto detto poc’anzi, la semplicità del programma viene anche palesata dalla semplicità e brevità del file di configurazione.
Filtraggio dei contenuti
Il filtraggio dei contenuti Web del proxy, pur non avendo e non volendo avere la completezza (e “laboriosità”) dell’accoppiata Squid/DansGuardian, si basa sul contenuto del file /etc/tinyproxy/filter, il quale conterrà una lista di espressioni regolari, una per riga, corrispondenti all’insieme dei domini o semplici URL da bloccare. La logica di blocking può essere sia a whitelist che a blacklist.











